What are hurdle models?
Google explains best,
The hurdle model is a two-part model that specifies one process for zero counts and another process for positive counts. The idea is that positive counts occur once a threshold is crossed, or put another way, a hurdle is cleared.
— Getting started with hurdle models [University of Virginia Library]
What are hurdle models useful for?
Many statistical learning models—particularly linear models—assume some level of normality in the response variable being predicted. If we have a dataset with a heavily skewed response or one which contains extreme outliers, it is a common practice to apply something like a Box-Cox power transformation before fitting.
But what do you do if you come across a clearly multi-modal distribution like the one below? Applying a power transform here will just change the scale of the variable, it won’t help with the fact that there is a huge spike of values at zero. The fact that it is multi-modal is a good indicator that we are over-aggregating data which belong to two or more distinct underlying data generation processes.
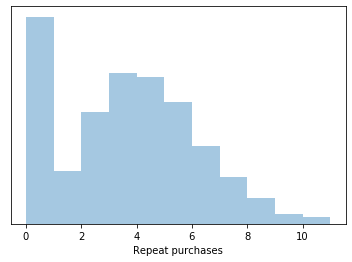
Distributions like this are commonly seen when analyzing composite variables such as insurance claims, where some large proportion are zero, but then the proportion of non-zero values take on a distribution of their own. Breaking down these sorts of distributions into their component parts allows us to more effetively model each piece and then recombine them at a later stage.
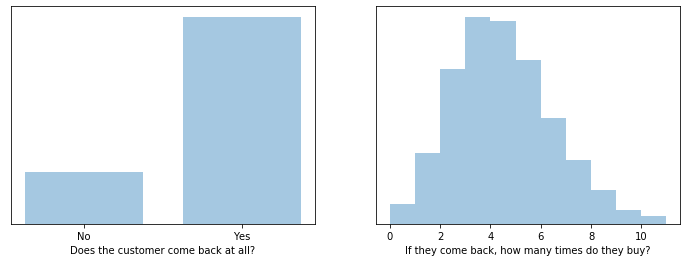
In the toy example above we have two underlying processes: Does a customer come back? If so, how many purchases does he or she make? The first is modeled as a binomial random variable (coin flip) and the second as a $ \text{Pois}(\lambda=4) $ random variable, which represents discrete event counts.
How can I implement a hurdle model?
So we want to fit and predict two sub-models, and then multiply their predictions together:
- A classifier, trained and tested on all of our data.
- A regressor, trained only on true positive samples, but used to make predictions on all test data.
The most straightforward way to achieve this would be to just train two separate models, make predictions on the same test dataset, and multiply their predictions together before evaluating. However with this approach we lose the ability to interface our model with the rest of the scikit-learn ecosystem, including passing it into GridSearchCV or any of the evaluation functions such as cross_val_predict.
A better approach is to implement our hurdle model as a valid scikit-learn estimator object by extending from the provided BaseEstimator class.
Making it a valid Scikit-Learn estimator
The code snippet above may feel like it is longer than it needs to be. This is primarily because I tried to write it as a valid scikit-learn estimator, which I learned involves jumping through a few hoops so that it is compatible with other sklearn functions, including:
- Init variables must each be of a data type which evaluates as equal when compared with another copy of itself. This is necessary because sklearn clones estimators behind the scenes to do parallel processing in functions such as
GridSearchCv. Primitive datatypes (e.g.'yo' == 'yo'and42 == 42) pass this test, but already-initialized estimators to use as sub-models do not. Because of this, I pass model type as a string, then use the_resolve_estimatormethod to instantiate the actual estimator. - The
fitmethod returns the estimator itself, to enable method chaining. - The attribute
self.is_fitted_is set by the.fit()method and then checked by.predict(). - Any input is validated using the
check_array()function before being fit or predicted.
Scikit-learn provides a check_estimator function which runs a battery of automated tests against your estimator. I learned most of these requirements above while attempting to pass these tests.
Further reading
Rolling your own estimator [scikit-learn docs] – Provides a good overview of how to write your own estimator
Github / NeverForged / Hurdle [Github] – I used this as a starting point for my code.
Creating your own estimator in scikit-learn – Some additional concerns w.r.t GridSearchCV