Motivation
I put together an emoji search Alfred workflow which uses alfy to filter this JSON file of emoji.
There are plenty of existing emoji Alfred workflows around, but I wanted one that allowed me to edit the aliases for individual emoji.
The one missing piece was to have the workflow display the emoji itself as the icon for each result. The Alfred Script Filter JSON Format includes an icon field, but it expects the path to an actual icon file on disk.
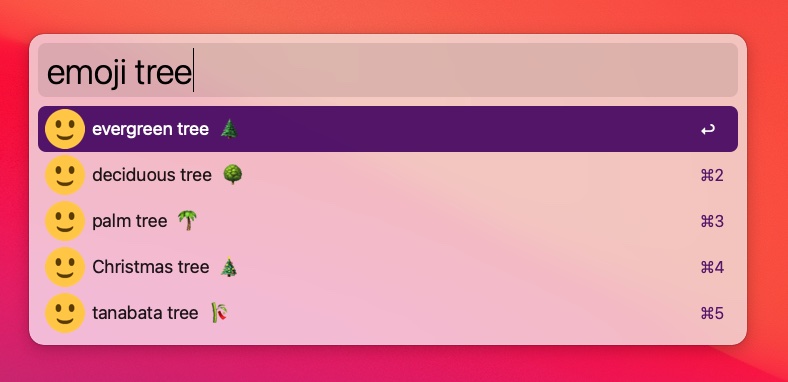
This simply will not do!
Read list of emoji
First, let’s read in the emoji.json file mentioned above.
import json
with open('emoji.json', 'r') as f:
emoji_json = json.loads(f.read())
print(f'Number of emoji: {len(emoji_json)}')
Number of emoji: 1812
Here are the first 100 emoji contained inside.
for e in emoji_json[0:100]:
print(e['emoji'], end=' ')
😀 😃 😄 😁 😆 😅 🤣 😂 🙂 🙃 😉 😊 😇 🥰 😍 🤩 😘 😗 ☺️ 😚 😙 🥲 😋 😛 😜 🤪 😝 🤑 🤗 🤭 🤫 🤔 🤐 🤨 😐 😑 😶 😶🌫️ 😏 😒 🙄 😬 😮💨 🤥 😌 😔 😪 🤤 😴 😷 🤒 🤕 🤢 🤮 🤧 🥵 🥶 🥴 😵 😵💫 🤯 🤠 🥳 🥸 😎 🤓 🧐 😕 😟 🙁 ☹️ 😮 😯 😲 😳 🥺 😦 😧 😨 😰 😥 😢 😭 😱 😖 😣 😞 😓 😩 😫 🥱 😤 😡 😠 🤬 😈 👿 💀 ☠️ 💩
Easy mode: Twitter emoji
I found the emojificate library, which makes straightforward use of the Twemoji CDN to fetch various sizes of Twitter-style emoji.
from IPython.display import Image
def get_png_url(char: str) -> str:
""" Pulled from: https://github.com/glasnt/emojificate/blob/latest/emojificate/filter.py"""
cdn_fmt = "https://twemoji.maxcdn.com/v/latest/72x72/{codepoint}.png"
def codepoint(codes):
# See https://github.com/twitter/twemoji/issues/419#issuecomment-637360325
if "200d" not in codes:
return "-".join([c for c in codes if c != "fe0f"])
return "-".join(codes)
return cdn_fmt.format(codepoint=codepoint(["{cp:x}".format(cp=ord(c)) for c in char]))
url = get_png_url('🐿️')
Image(url)

import requests
from tqdm.notebook import tqdm
from IPython.display import clear_output
def download_png(url: str, name: str) -> None:
"""Download a specific png file to disk."""
with open(f'twitter-icons/{name}.png', 'wb') as f:
img_data = requests.get(url).content
f.write(img_data)
for e in tqdm(emoji_json, total=len(emoji_json)):
fp = e['description'].replace(' ', '-')
url = get_png_url(e['emoji'])
download_png(url, fp)
clear_output()
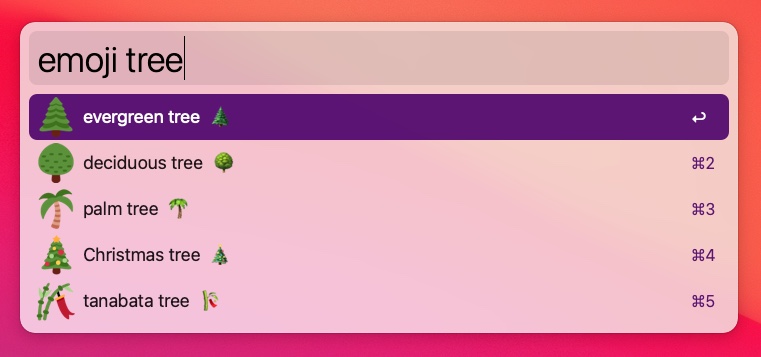
That was easy!
Hard mode: scraping from unicode.org
The above works perfectly for twitter emoji, but what if we want the apple emoji?
Inspired by this StackOverflow question—Programmatically get a PNG for a unicode emoji—we could also scrape icons from this page: https://unicode.org/emoji/charts/full-emoji-list.html.
Fetch HTML
emoji_page_html = requests.get('https://unicode.org/emoji/charts/full-emoji-list.html').text
Strip variation selectors
One small gotcha here—which will otherwise mess with our regex matches—is that some emoji are optionally followed by an invisible variation selector character. This is meant to specify that the character should be rendered as emoji rather than as icons, but this seems to be appended to many emoji which don’t have obvious icon representations, such as the chipmunk 🐿️.
We’ll strip these (trailing) characters from our emoji.json inputs, and write our regex to optionally match them, if present in the unicode table.
import re
import pandas as pd
def strip_variation_electors(emoji: str) -> str:
return re.sub(u'[\ufe00-\ufe0f]$', '', emoji)
emoji_df = (
pd.DataFrame(emoji_json)
.assign(emoji=lambda x: x['emoji'].apply(strip_variation_electors))
.assign(
name=lambda x: x['description'].apply(lambda x: x.replace(' ', '-')),
length=lambda x: x['emoji'].apply(len),
split=lambda x: x['emoji'].apply(list)
)
.loc[:, ['name', 'emoji', 'length']]
)
emoji_df['length'].value_counts()
1 1320
2 258
3 190
4 13
5 13
7 12
8 3
6 3
Name: length, dtype: int64
Extract using regex
def extract_emoji_from_html(emoji: str, version=0) -> str:
#html_search_string = r"<img alt='{}' class='imga' src='data:image\/png;base64,([^']+)'>"
html_search_string = r"<img alt='{}(?:[\ufe00-\ufe0f])?'(?: title='.+')? class='imga' src='data:image\/png;base64,([^']+)'>"
matchlist = re.findall(html_search_string.format(emoji), emoji_page_html)
return matchlist[version]
emoji_b64 = {}
for _, df in tqdm(emoji_df[['name', 'emoji']].iterrows(), total=emoji_df.shape[0]):
name, emoji = df['name'], df['emoji']
try:
emoji_b64[name] = extract_emoji_from_html(emoji)
except IndexError:
pass
clear_output()
len(emoji_b64)
1811
Check results
is_found = pd.DataFrame({'is_found': 1}, index=emoji_b64.keys()).sort_index()
joined = (
pd.merge(emoji_df.set_index('name'), is_found, left_index=True, right_index=True, how='left')
.fillna(0)
)
#joined.groupby('length')['is_found'].mean()
joined.loc[lambda x: x['is_found'] == 0]
| emoji | length | is_found | |
|---|---|---|---|
| name | |||
| keycap:-* | *️⃣ | 3 | 0.0 |
Write to files
import base64
for name, img_data in emoji_b64.items():
b64 = base64.b64decode(img_data)
with open(f'apple-icons/{name}.png', 'wb') as f:
f.write(b64)
clear_output()
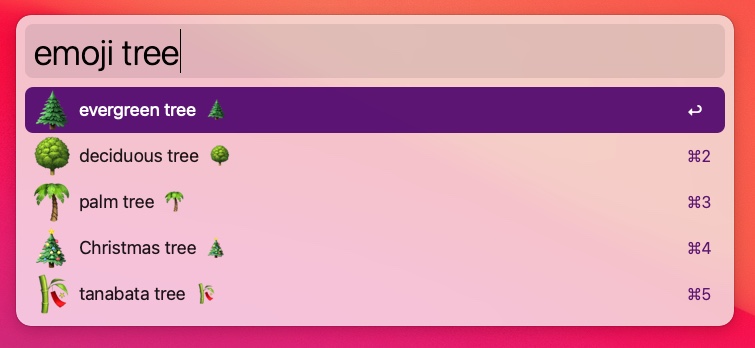
Success!
Appendix: multi-character emoji
import pandas as pd
emoji_df = (
pd.DataFrame(emoji_json)
.assign(
name=lambda x: x['description'].apply(lambda x: x.replace(' ', '-')),
split=lambda x: x['emoji'].apply(lambda x: [x.replace('', 'ZWJ').replace('️', 'VS') for x in list(x)]),
length=lambda x: x['emoji'].apply(len)
)
.loc[:, ['name', 'emoji', 'length', 'split']]
)
emoji_df['length'].value_counts()
What is going on here?!
Length-two
Most (but not all) of these emoji are unchanged by stripping the trailing variation selector character.
(
emoji_df
.loc[lambda x: (x['length'] == 2) & (x['split'].apply(lambda x: x[-1]) == 'VS')]
.assign(stripped=lambda x: x['emoji'].apply(lambda y: y.strip('️')))
.sample(10)
)
Besides trailing variation selectors, some length-two emoji are emoji flag sequences, which are made up of two “regional indicator” characters.
(
emoji_df
.loc[lambda x: x['length'] == 2, :]
.loc[lambda x: x['emoji'].apply(lambda y: list(y)[1]) != '️']
.sample(5)
)
Length-three
Most length-three emojis are created by joining multiple emojis together using a zero-width joiner character.
emoji_df.loc[lambda x: x['length'] == 3, :].head(30).sample(10)
Length-four
Emoji of length four seem to be composites of two other emoji, a ZWJ, and a seemingly unnecessary variation selector.
(
emoji_df.loc[lambda x: x['length'] == 4]
.assign(stripped=lambda x: x['emoji'].apply(lambda y: y.strip('️')))
)
Length-five
Length five emoji seem to be some combination of:
- Sequences of two emoji, incl. two unnecessary variation selector characters.
- Sequendes of three emoji, joined by two ZWJ.
(
emoji_df
.loc[lambda x: x['length'] == 5]
.assign(stripped=lambda x: x['emoji'].str.replace('️', ''))
.assign(length_stripped=lambda x: x['stripped'].apply(len))
)