After taking a course on Machine Learning for Trading, I decided to apply some of the concepts I had learned to model my own stock trading performance. Unfortunately this was not nearly as straightforward as I expected, since my trade history included a number of stocks which no longer exist.
How do you find the share price of an unlisted company?
There are a number of good free sources for market data such as Yahoo Finance or Google Finance. It is easy to pull this data into python using something like the yfinance package. But these sources generally only contain data for currently listed stocks. My trade history includes a number of iShares ETFs which no longer exist, including one in particular: AAIT. In my case, the ticker still exists in Yahoo Finance, but the data is clearly broken.
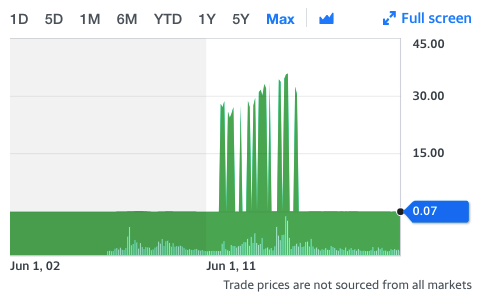
Does not seem like a random walk to me
There are a number of paid sources for historical data of unlisted companies, but I can’t justify paying $40 for data I am just using to scratch my own curiosity. After a bit of googling, I found some price data for AAIT on a 90s-styled website historicalstockprice.com. Unfortunately it only lets you view a single day at a time, and has no option for csv export. On the bright side, this presented a good opportunity to play around with the BeautifulSoup python library.
UPDATE
I later found that investing.com has data for a number of unlisted stocks, including AAIT. It also lets you easily download a CSV file with daily prices. So you probably want to check that source before going to all the effort of writing a scraper from scratch.
Building a simple web scraper
Find the actual URL to scrape
The first step is to figure out the actual URL we need to scrape. Let’s start with the actual webpage itself.
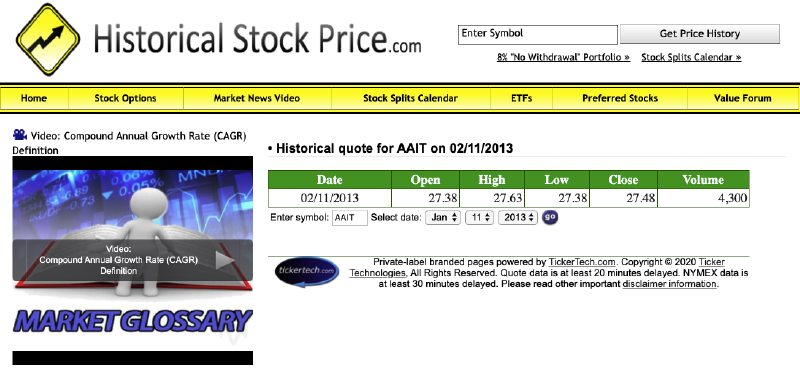
Scraping was just easier in the ’90s.
But if we look at the actual source code for the page (Right-click → View Page Source in Google Chrome) it appears that the price data is not there. So it seems that the price data is loaded from some other API—likely using javascript—after the page itself loads. If we disable javascript and reload the page, it confirms our suspicions.

With javascript disabled, our page does not contain any price data 😭
After reading through the source code, it is apparent that the page loads its contents from a secondary URL, which is the actual URL we want to scrape.

Now we’re making progress!
Write a scraper using BeautifulSoup
The URL contains parameters for ticker, year, month, and date, so we just need to loop over our date range of interest, format the URL template with the appropriate parameters, and make an API call.
We are interested in the contents of the cell under “Close”. Ideally the response would contain a page with CSS classes and IDs, which we could use to cleverly select the appropriate element, but in our case there are no classes or IDs. But since the page always has the exact same structure, we can just take the contents of the fifth td element of the second table element.
import pandas as pd
import matplotlib.pyplot as plt
from tqdm.notebook import tqdm
import requests
from bs4 import BeautifulSoup
def scrape_hsp(ticker: str, start_date: str, end_date: str) -> pd.Series:
""" Scrape ticker data from historicalstockprice.com """
URL = 'https://www.tickertech.net/etfchannel/cgi/?a=historical&ticker={TICKER}&month={MM}&day={DD}&year={YYYY}'
date_range = pd.bdate_range(start_date, end_date)
prices = pd.Series(index=date_range, dtype=float)
for dt in tqdm(date_range, unit='days'):
year, month, day = dt.strftime('%Y-%m-%d').split('-')
formatted_url = URL.format(TICKER=ticker, MM=month, DD=day, YYYY=year)
page = requests.get(formatted_url)
soup = BeautifulSoup(page.content, 'html.parser')
try:
val = soup.findAll('table')[1].find_all('td')[4].find('font').contents[0]
prices.loc[dt] = float(val)
except IndexError:
continue
return prices
prices = scrape_hsp(ticker='AAIT', start_date='2013-01-01', end_date='2015-08-28')
HBox(children=(FloatProgress(value=0.0, max=694.0), HTML(value='')))
This takes 7-13 minutes to run for our selected date range, which is acceptable. If we needed to scrape a much larger date range or a number of symbols, we could use the multiprocessing library to make concurrent requests.
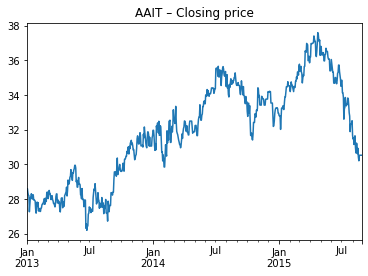
When we visualize the data below, we see that we’ve got a reasonable time series of price data!
prices.bfill().plot()
plt.title('AAIT – Closing price');
Further reading
Beautiful Soup: Build a Web Scraper With Python (Real Python) – Provides a good introduction to the BeautifulSoup python library, which is the most popular and well-documented library for building a scraper.