I love jupyter notebooks. As a data scientist, notebooks are probably the fundamental tool in my daily worflow. They fulfill multiple roles: documenting what I have tried in a lab notebook for the benefit of my future self, and also serving as a self-contained format for the final version of an analysis, which can be committed to our team git repo and then discovered or reproduced later by other members of the team.
The drawbacks of notebooks
But notebooks are not perfect. They introduce a number of problems, including—but not limited to:
- Modularity – reusable chunks of code tend to remain in notebooks rather than being extracted into their own modules—or even packages—as frequently as they should.
- Best practices – non-linear execution and global state are great for prototyping, but also make it cumbersome to refactor code later, or to write automated tests.
- Version control – Even if you do extract key functionality into their own modules, it becomes hard to keep track of these changes in github, because they are dwarfed by pull requests which contain ±10k lines of code, caused by the JSON representation of raw jupyter notebooks.
Presenting your results to non-technical stakeholders
A critical junction arises near the end of any data science project—how will you share results with the relevant stakeholders? The tool of choice in many organisations—at least my own—tends to be Google Slides. Unfortunately I have created more than a few slide decks whose contents almost entirely consist of matplotlib pngs, copy–pasted directly from a jupyter notebook notebook. This is sub-optimal, because it causes a disconnect between code and content. Future re-runs of your notebook, perhaps with fixed or fresh data, will not automatically update the visualizations in those slides. This decoupling counteracts much of the benefit of reproducibility which the notebook format promises in the first place.
What stops us from presenting the notebook itself?
Jupyter notebooks have built-in support for Markdown and HTML, so you can embed rich content and largely control formatting. The main obstacle to presentation-quality notebooks seems to be managing attention.
- It’s difficult to focus the attention of your audience on a single thing like you can with slides.
- Although we want to keep code (input cells) for reproducability’s sake, showing it is distracting.
Take for example, the screenshot below of an HTML output of a raw Jupyter notebook. Notice that the majority of our “above the fold” content here is irrelevant to almost any potential audience of the notebook. Only 20% of the height is made up of details around the analysis.
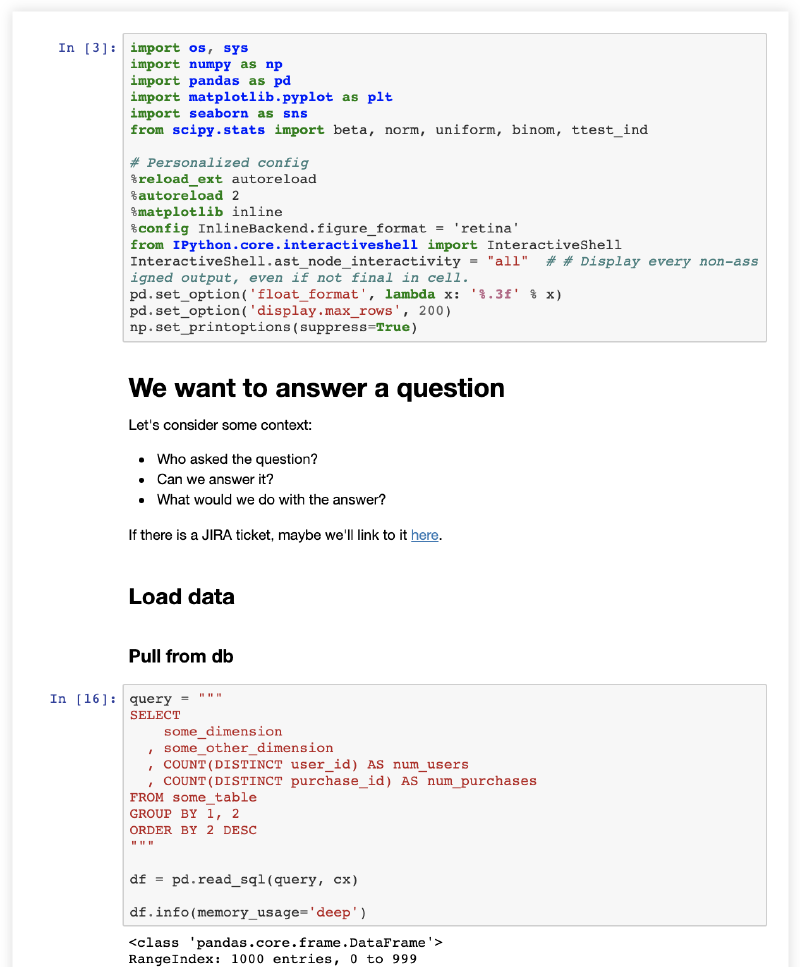
Not something you’d want to share with a stakeholder.
Existing attempts to solve this problem
Slides
One solution I’ve seen—most frequently used to give technical taks, e.g. at JupyterCon—are slides built using the RISE extension. These definitely solve our first problem—focusing the audience’s attention—but don’t address the second. In fact, they seem best suited for presentations where the code itself is an integral part of what is being presented. I suspect that’s why it appears so frequently in technical talks, but less frequently elsewhere.
nbconvert with –no-input flag
Nbconvert has a built-in flag to hide input, but unfortunately it seems to result in a poorly formatted final output, in which the output of code cells is not aligned with the markdown cells.
jupyter nbconvert my_notebook.ipynb --no-input

Still not something you’d want to share with a stakeholder.
Static website generator
If you don’t need slides specifically, and if you are interested in building up a consistent experience for your entire team, it might be worth using a static website generator to build a sort of knowledge repo from multiple notebooks. This is less well-suited for sharing a single notebook, particularly if you don’t feel like deploying a site to host the output.
A solution using nbconvert templates
If you are primarily intersted in having a clean and shareable report rather than slides, it is possible to achieve this with vanilla nbconvert, rather than adding dependenies on external packages. The best solution I found was this nbconvert template by Damian Avila, which uses jQuery to add toggle functionlity, such that the code is initially hidden but can be displayed by clicking on the output of any cell.
It is easy to use:
- Download the toggle.tpl template file.
- Figure out where your jupyter template directory is, by running
from jupyter_core.paths import jupyter_path; print(jupyter_path('nbconvert','templates')) - Copy the template file to that directory.
- From the command line in the directory containing your notebook, run
jupyter nbconvert my_notebook.ipynb --template=toggle
Here’s what our output looks like after using nbconvert with a template to hide code cells.

An output you can proudly share with stakeholders.
What an improvement from our first attempt! In this (somewhat contrived example) our entire document now fits “above the fold”. More importantly, the audience can easily grok the structure of the document and scan it visually.
Bonus: useful jupyter notebook extensions
Jupyter has a useful package called nbextensions which provides a bunch of extended functionality to your notebooks. There are two extensions in particular which are useful for our purposes.
Previewing final “hidden” output from your notebook
There are a few nbextensions related to hiding code cells, but my favourite is Hide input all, which can be used to fold all cells in your notebook in a single click. This is great for previewing what the final html output will look like from within the notebook itself. rather than having to run the full nbconvert command each time.
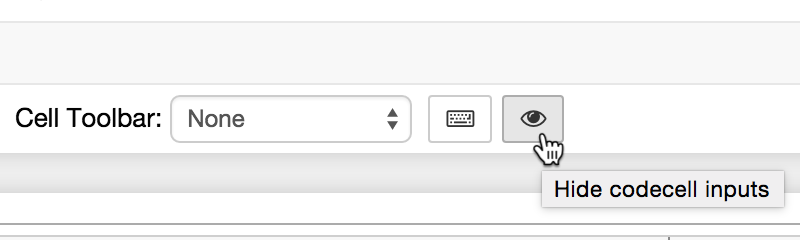
Clicking a single button hides all input cells in your notebook.
Adding clickable links to section headers
Another great nbextension is Table of Contents (2), which builds a dynamically-updated ToC based on the markdown headings in a notebook. This serves as a good outline during editing, useful for reviewing and revising the macro-level structure of our document. The table is rendered with clickable links in the final html output, which enables readers to navigate through a large report by jumping right to a particular section.